在 CentOS 7 中安装 Hadoop 与 HBase
本实验在 VMware 虚拟机中安装 CentOS 系统,搭建 Hadoop 伪分布式模式环境,安装 HBase。实验必要的环境,包括:VMware Workstation Pro 15, CentOS 7.6.1810, Java SE Development Kit 8u201, Hadoop 2.9.2, HBase 1.4.9。
下载地址:
- VMware Workstation Pro 15:https://pan.baidu.com/s/1LO6DxDw71vecyfvsJXv1jA 提取码: 98kc
- CentOS:CentOS-7-x86_64-Minimal-1810.iso
- Java SDK:jdk-8u201-linux-x64.tar.gz
- Hadoop:hadoop-2.9.2.tar.gz
- HBase:hbase-1.4.9-bin.tar.gz
本报告一共分为四个部分
- 第一部分:在 VMware 中安装 CentOS
- 第二部分:安装 Java,并配置环境变量
- 第三部分:安装并配置 Hadoop(伪分布式模式)
- 第四部分:安装并配置 HBase
第一部分:在 VMware 中安装 CentOS
安装完成后使用 SSH 客户端连接到虚拟机。
由于写此报告时已经安装完成,并没有将过程截图,此部分略。
设置 CentOS 的部分命令(均使用 root 用户执行):
关闭防火墙:
1
2$ systemctl stop firewalld.service #停止firewall
$ systemctl disable firewalld.service #禁止firewall开机启动关闭 selinux:
1
$ vim /etc/sysconfig/selinux
修改
SELINUX=enabled为SELINUX=disabled,如图
第二部分:安装 Java,并配置环境变量
安装 Java
进入实验目录,这里选择在 /opt/app 目录下,下载 Java SDK 安装包
1 | $ cd /opt/app |
使用如下命令解压:tar zxvf ./jdk-8u201-linux-x64.tar.gz,得到目录 /opt/app/jdk1.8.0_201。
添加环境变量
修改配置文件,执行 vim /etc/profile,在尾部添加
1 | export JAVA_HOME="/opt/app/jdk1.8.0_201" |
如图

修改完毕后,执行命令 source /etc/profile 使其生效。
执行命令 java -version,看到下图,即为安装成功

第三部分:安装并配置 Hadoop(伪分布式模式)
安装 Hadoop
下载 Hadoop 2.9.2 安装包
1 | $ wget http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.9.2/hadoop-2.9.2.tar.gz |
使用如下命令解压:tar zxvf ./hadoop-2.9.2.tar.gz,得到目录 /opt/app/hadoop-2.9.2。
添加环境变量
修改配置文件,执行 vim /etc/profile,在尾部添加
1 | export HADOOP_HOME="/opt/app/hadoop-2.9.2" |
如图

修改完毕后,执行 source /etc/profile 使其生效。
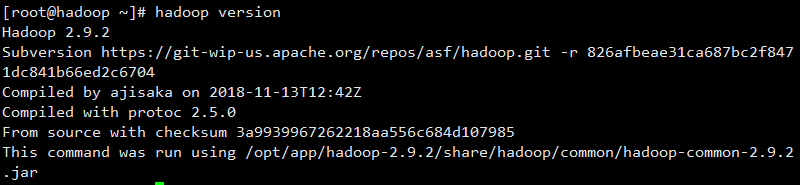
执行 hadoop version,看到下图,即为安装成功
配置 Hadoop
修改
hadoop-env.sh执行命令
1
$ vim /opt/app/hadoop-2.9.2/etc/hadoop/hadoop-env.sh
修改文件中的
JAVA_HOME参数为 Java 安装路径,结果如图
配置
core-site.xml执行命令
1
$ vim /opt/app/hadoop-2.9.2/etc/hadoop/core-site.xml
添加如下配置
1
2
3
4
5
6
7
8
9
10<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.29.127:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/data/tmp</value>
</property>
</configuration>其中
fs.defaultFS参数配置的是 HDFS 的地址,192.168.29.127为本虚拟机 IP 地址。hadoop.tmp.dir参数配置的是 Hadoop 临时目录,这里设置为/opt/data/tmp,并手动创建此目录。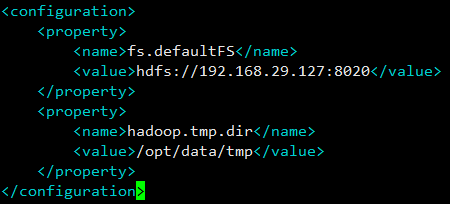
配置
hdfs-site.xml执行命令
1
$ vim /opt/app/hadoop-2.9.2/etc/hadoop/hdfs-site.xml
添加如下配置
1
2
3
4
5
6<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>dfs.replication参数配置的是 HDFS 存储时的备份数量,因为这里是伪分布式环境只有一个节点,所以这里设置为 1。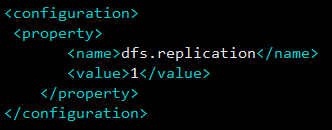
格式化 HDFS
执行命令
hdfs namenode -format,当配置文件中设置的临时目录/opt/data/tmp下出现dfs文件夹时,说明格式化成功。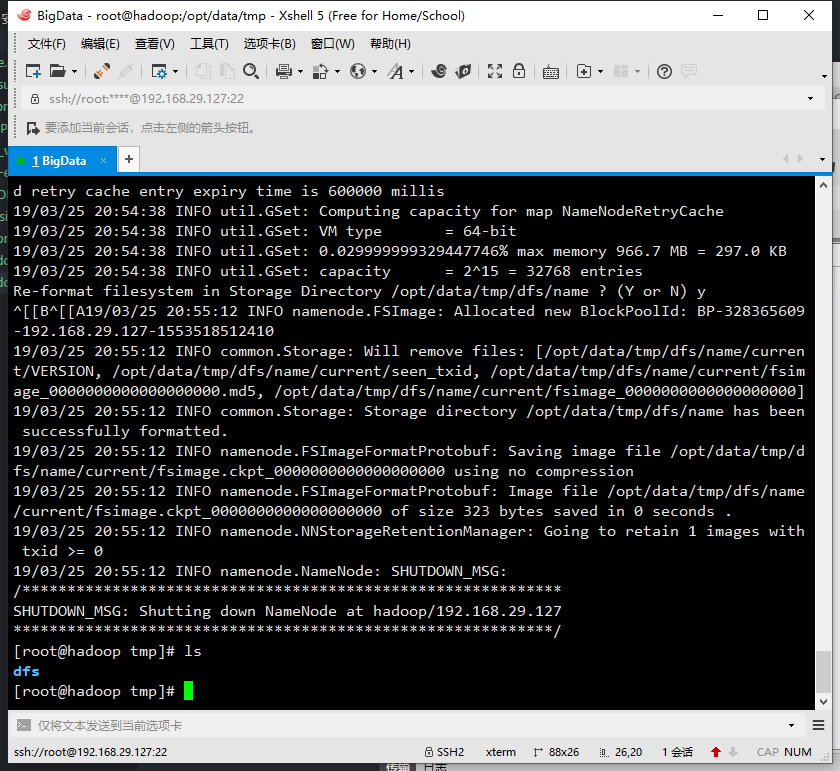
配置
mapred-site.xml默认没有
mapred-site.xml文件,从mapred-site.xml.template模板文件复制生成mapred-site.xml。在 Hadoop 目录下执行命令
1
$ cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
打开
mapred-site.xml,添加如下配置1
2
3
4
5
6<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>此处设置
mapreduce.framework.name参数指定 mapreduce 运行在 yarn 框架上。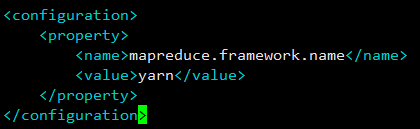
配置
yarn-site.xml执行命令
1
$ vim /opt/app/hadoop-2.9.2/etc/hadoop/yarn-site.xml
添加如下配置
1
2
3
4
5
6
7
8
9
10<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.29.127</value>
</property>
</configuration>yarn.nodemanager.aux-services配置了 yarn 的默认混洗方式,选择为 mapreduce 的默认混洗算法。yarn.resourcemanager.hostname指定了 Resourcemanager 运行在哪个节点上,此处为本虚拟机 IP。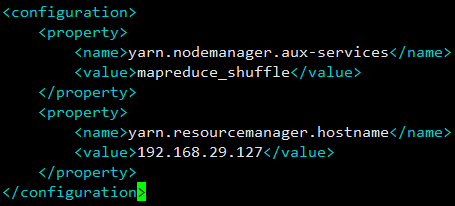
设置免密登录
关于免密登录详细的可以查看 Linux 笔记
通常 Hadoop 集群中的各个机器间会相互地通过 SSH 访问,每次访问都输入密码是不现实的,所以要配置免密登录。
这里是伪分布式的,所以只给本机配置就 OK 了。
在本机上生成公钥
执行命令
1
$ ssh-keygen -t rsa
一路回车,都设置为默认值,然后再当前用户的目录下的
.ssh目录中会生成公钥文件id_rsa.pub和私钥文件id_rsa。
分发公钥
1
$ ssh-copy-id 192.168.29.127 ## 后面填写目的地址,此处是本机IP
至此,开启和关闭 Hadoop 服务都无需输入密码。
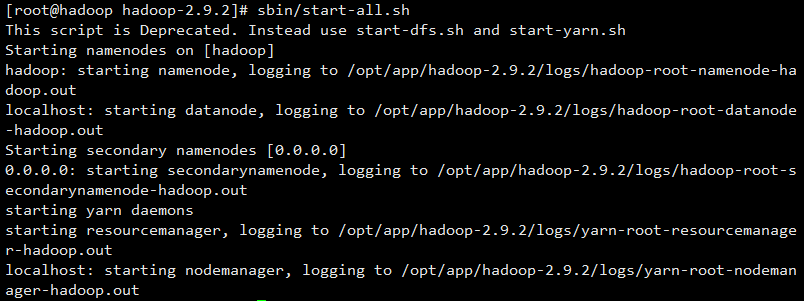
启动 Hadoop
在 Hadoop 目录下执行命令 sbin/start-all.sh,开始启动 Hadoop
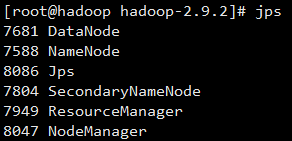
运行命令 jps 可以看到服务均开始运行
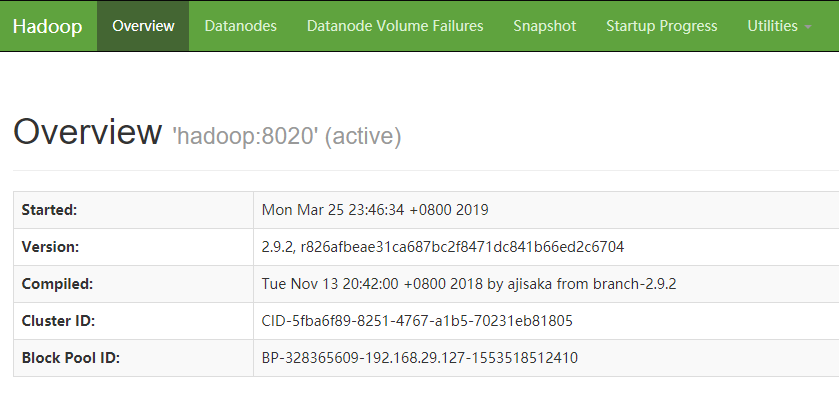
进入 http://192.168.27.127:50070 ,可以看到 Namenode 状态为 “active”。
Hadoop 指定 SSH 连接的端口号
当因为某些原因自定义 SSH 端口号的时候,使用以下方法告诉 Hadoop 你的 SSH 端口号。
编辑 Hadoop 目录下 /etc/hadoop/hadoop-env.sh,添加
1 | export HADOOP_SSH_OPTS="-p xxx" //xxx为自定义的SSH端口号 |
第四部分:安装并配置 HBase
安装 HBase
下载 HBase 1.4.9 安装包
1 | $ wget http://mirrors.tuna.tsinghua.edu.cn/apache/hbase/1.4.9/hbase-1.4.9-bin.tar.gz |
使用如下命令解压:tar zxvf hbase-1.4.9-bin.tar.gz,得到目录 /opt/app/hbase-1.4.9。
添加环境变量
修改配置文件,执行 vim /etc/profile,在尾部添加
1 | export HBASE_HOME=/opt/app/hbase-1.4.9 |
如图

修改完毕后,执行 source /etc/profile 使其生效。
执行 hbase version,看到下图,即为安装成功

配置 HBase
配置
hbase-site.xml执行命令
1
$ vim /opt/app/hbase-1.4.9/conf/hbase-site.xml
添加如下配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://192.168.29.127:8020/hbase</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/opt/data/hbase/tmp</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>false</value>
</property>
</configuration>hbase.rootdir配置的这个目录是 region server 的共享目录,用来持久化 HBase。hbase.tmp.dir指定了 HBase 的临时目录。hbase.cluster.distributed配置 HBase 的运行模式,false 是单机模式,true 是分布式模式。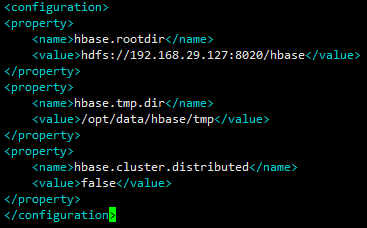
配置
hbase-env.sh执行命令
1
$ vim /opt/app/hbase-1.4.9/conf/hbase-env.sh
添加如下配置
1
2
3
4export JAVA_HOME=/opt/app/jdk1.8.0_201
export HADOOP_HOME=/opt/app/hadoop-2.9.2
export HBASE_HOME=/opt/app/hbase-1.4.9
export HBASE_CLASSPATH=/opt/app/hadoop-2.9.2/etc/hadoop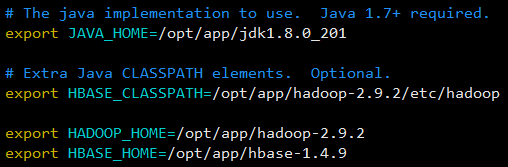
启动 HBase
在启动 HBase 前先启动 Hadoop
在 HBase 目录下执行命令 bin/start-hbase.sh,看到以下状态

查看 Java 进程:jps
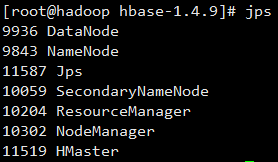
可以看到 HMaster 进程已经启动了。
至此,Hadoop 和 HBase 在 CentOS 7 上的安装已全部完成。
在 CentOS 7 中安装 Hadoop 与 HBase