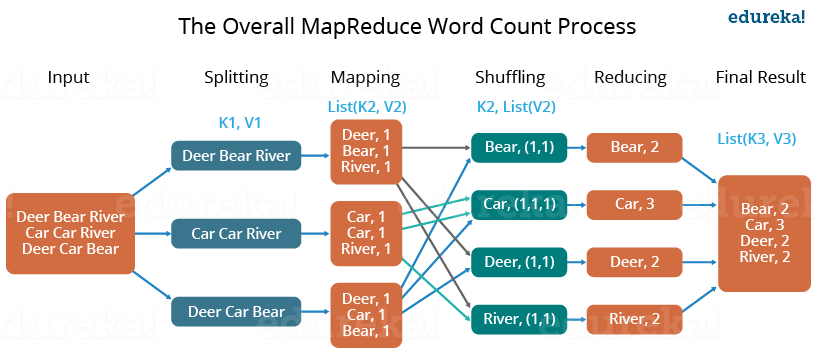
HDFS 和 MapReduce 是 Hadoop 的两个重要核心,其中 MapReduce 是 Hadoop 的分布式计算模型。MapReduce 主要分为两步 Map 步和 Reduce 步,引用网上流传很广的一个故事来解释,现在你要统计一个图书馆里面有多少本书,为了完成这个任务,你可以指派小明去统计书架 1,指派小红去统计书架 2,这个指派的过程就是 Map 步,最后,每个人统计完属于自己负责的书架后,再对每个人的结果进行累加统计,这个过程就是 Reduce 步。
本代码运行环境为 ubuntu 18.04,使用 Hadoop 2.9.2 版本在 CentOS 7 中安装 Hadoop 与 HBase )搭建并启动 Hadoop
MapReduce 原理 分析 MapReduce 执行过程 MapReduce 运行的时候,会通过 Mapper 运行的任务读取 HDFS 中的数据文件,然后调用自己的方法,处理数据,最后输出。Reducer 任务会接收 Mapper 任务输出的数据,作为自己的输入数据,调用自己的方法,最后输出到 HDFS 的文件中。
Mapper 任务的执行过程详解 每个 Mapper 任务是一个 java 进程,它会读取 HDFS 中的文件,解析成很多的键值对,经过我们覆盖的 map 方法处理后,转换为很多的键值对再输出。整个 Mapper 任务的处理过程又可以分为以下六个阶段。
第一阶段是把输入文件按照一定的标准分片 (InputSplit),每个输入片的大小是固定的。默认情况下,输入片 (InputSplit) 的大小与数据块 (Block) 的大小是相同的。如果数据块 (Block) 的大小是默认值 64MB,输入文件有两个,一个是 32MB,一个是 72MB。那么小的文件是一个输入片,大文件会分为两个数据块,那么是两个输入片。一共产生三个输入片。每一个输入片由一个 Mapper 进程处理。这里的三个输入片,会有三个 Mapper 进程处理。
第二阶段是对输入片中的记录按照一定的规则解析成键值对。有个默认规则是把每一行文本内容解析成键值对。“键” 是每一行的起始位置 (单位是字节),“值” 是本行的文本内容。
第三阶段是调用 Mapper 类中的 map 方法。第二阶段中解析出来的每一个键值对,调用一次 map 方法。如果有 1000 个键值对,就会调用 1000 次 map 方法。每一次调用 map 方法会输出零个或者多个键值对。
第四阶段是按照一定的规则对第三阶段输出的键值对进行分区。比较是基于键进行的。比如我们的键表示省份(如北京、上海、山东等),那么就可以按照不同省份进行分区,同一个省份的键值对划分到一个区中。默认是只有一个区。分区的数量就是 Reducer 任务运行的数量。默认只有一个 Reducer 任务。
第五阶段是对每个分区中的键值对进行排序。首先,按照键进行排序,对于键相同的键值对,按照值进行排序。比如三个键值对 <2,2>,<1,3>,<2,1>,键和值分别是整数。那么排序后的结果是 <1,3>,<2,1>,<2,2>。如果有第六阶段,那么进入第六阶段;如果没有,直接输出到本地的 linux 文件中。
第六阶段是对数据进行归约处理,也就是 reduce 处理。键相等的键值对会调用一次 reduce 方法。经过这一阶段,数据量会减少。归约后的数据输出到本地的 linxu 文件中。本阶段默认是没有的,需要用户自己增加这一阶段的代码。
Reducer 任务的执行过程详解 每个 Reducer 任务是一个 Java 进程。Reducer 任务接收 Mapper 任务的输出,归约处理后写入到 HDFS 中,可以分为几个阶段。
第一阶段是 Reducer 任务会主动从 Mapper 任务复制其输出的键值对。Mapper 任务可能会有很多,因此 Reducer 会复制多个 Mapper 的输出。
第二阶段是把复制到 Reducer 本地数据,全部进行合并,即把分散的数据合并成一个大的数据。再对合并后的数据排序。
第三阶段是对排序后的键值对调用 reduce 方法。键相等的键值对调用一次 reduce 方法,每次调用会产生零个或者多个键值对。最后把这些输出的键值对写入到 HDFS 文件中。在整个 MapReduce 程序的开发过程中,我们最大的工作量是覆盖 map 函数和覆盖 reduce 函数。
导入 MapReduce 的相关依赖
使用 Java 语言进行 MapReduce 操作首先需要导入必要的依赖
如果使用的是 maven 管理项目,则需要编辑项目目录的 pom.xml 文件
打开 pom.xml,在 <dependencies>...<dependencies> 之间加入:
1 2 3 4 5 <dependency > <groupId > org.apache.hadoop</groupId > <artifactId > hadoop-mapreduce-client-core</artifactId > <version > 2.9.2</version > </dependency >
如果不使用 Maven 管理,可以手动导入相关包。
Wordcount 实例
功能:统计每一个单词在整个数据集中出现的总次数
WordCount 实现的官方文档:Example: WordCount v1.0
Wordcount 整体流程 最简单的 MapReduce 应用程序至少包含 3 个部分:一个 Map 函数、一个 Reduce 函数和一个 main 函数。在运行一个 MapReduce 计算任务时候,任务过程被分为两个阶段:map 阶段和 reduce 阶段,每个阶段都是用键值对(key/value)作为输入(input)和输出(output)。main 函数将作业控制和文件输入 / 输出结合起来。
过程如图所示:
对一个有三行文本的文件进行 MapReduce 操作。
Map 过程 :并行读取文本,对读取的单词进行 map 操作,每个词都以 <key,value> 形式生成。
Reduce 过程 :对 map 的结果进行排序,合并,最后得出词频。
WordCount 代码实现 新建文件 input.txt,内容:
1 2 3 Deer Bear River Car Car River Deer Car Bear
将其上传到 HDFS 中,在终端运行:
1 2 3 hadoop fs -mkdir /wordcount hadoop fs -mkdir /wordcount/input hadoop fs -put input.txt /wordcount/input
完整代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;import java.util.StringTokenizer;public class WordCount { public static class TokenizerMapper extends Mapper <Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable (1 ); private Text word = new Text (); public void map (Object key, Text value, Context context) throws IOException, InterruptedException{ StringTokenizer itr = new StringTokenizer (value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } } public static class IntSumReducer extends Reducer <Text, IntWritable, Text, IntWritable> { private IntWritable result = new IntWritable (); public void reduce (Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException{ int sum = 0 ; for (IntWritable val : values){ sum += val.get(); } result.set(sum); context.write(key, result); } } public static void main (String[] args) throws Exception { Configuration conf = new Configuration (); Job job = Job.getInstance(conf, "Word Count" ); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path ("hdfs://localhost:8020/wordcount/input/input.txt" )); FileOutputFormat.setOutputPath(job, new Path ("hdfs://localhost:8020/wordcount/output" )); System.exit(job.waitForCompletion(true ) ? 0 : 1 ); } }
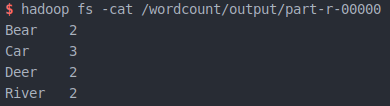
实验结果
运行程序,成功后可以看到在 /wordcount/output/ 下多出两个文件
其中第二个文件里为运行完成后的结果
WordCount 完成!
统计访问次数 统计用户在 2019 年度每个自然日的总访问次数。原始数据文件中提供了用户名称与访问日期。这个任务就是要获取以每个自然日为单位的所有用户访问次数的累加值。如果通过 MapReduce 编程实现这个任务,首先要考虑的是,Mapper 与 Reducer 各自的处理逻辑是怎样的;然后根据处理逻辑编写出核心代码;最后在 Idea 中编写完整代码,编译打包后提交给集群运行。
分析思路和逻辑
输入 / 输出格式。
这里社交网站用户的访问日期在格式上都属于文本格式,访问次数为整型数据格式。其组成的键值对为 <访问日期,访问次数>,因此 Mapper 的输出与 Reducer 的输出都选用 Text 类与 IntWritble 类。
Mapper 要实现的计算逻辑
Map 函数的主要任务是读取用户访问文件中的数据,输出所有访问日期与初始次数的键值对。<访问日期,1 >
Reducer 要实现的计算逻辑
读取 Mapper 输出的键值对 <访问日期,1>,进行累加。
user_login.txt 访问日期内容如下
将其上传到 HDFS 中,路径为 /DailyAccessCount/input
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 Nehru,2019-01-01 Dane,2019-01-01 Walter,2019-01-01 Gloria,2019-01-01 Clarke,2019-01-01 Madeline,2019-01-01 Kevyn,2019-01-01 Rebecca,2019-01-01 Calista,2019-01-01 Madeline,2019-01-02 Kevyn,2019-01-02 Rebecca,2019-01-03 Calista,2019-01-04 Walter,2019-03-12 Gloria,2019-03-12 Clarke,2019-03-12
程序代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class DailyAccessCount { public static class MyMapper extends Mapper <Object, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable (1 ); public void map (Object key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String array[] = line.split("," ); String keyOutput = array[1 ]; context.write(new Text (keyOutput), one); } } public static class MyReducer extends Reducer <Text, IntWritable, Text, IntWritable> { private IntWritable result = new IntWritable (); public void reduce (Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0 ; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } } public static void main (String[] args) throws Exception { Configuration conf = new Configuration (); Job job = Job.getInstance(conf, "Daily Access Count" ); job.setJarByClass(DailyAccessCount.class); job.setMapperClass(MyMapper.class); job.setReducerClass(MyReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path ("hdfs://localhost:8020/DailyAccessCount/input/user_login.txt" )); FileOutputFormat.setOutputPath(job, new Path ("hdfs://localhost:8020/DailyAccessCount/output" )); System.exit(job.waitForCompletion(true ) ? 0 : 1 ); } }
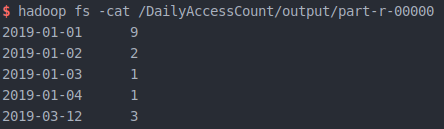
实验结果
运行程序,成功后可以看到在 /DailyAccessCount/output/ 下多出两个文件
其中第二个文件里为运行完成后的结果
统计访问次数完成!
统计每年最高气温 有如下文件 input_temperature.txt,其中 2010012325 表示在 2010 年 01 月 23 日的气温为 25 度。使用 MapReduce,计算每一年出现过的最大气温。
将其上传到 HDFS 中,路径为 /Temperature/input
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 2014010114 2014010216 2014010317 2014010410 2014010506 2012010609 2012010732 2012010812 2012010919 2012011023 2001010116 2001010212 2001010310 2001010411 2001010529 2013010619 2013010722 2013010812 2013010929 2013011023 2008010105 2008010216 2008010337 2008010414 2008010516 2007010619 2007010712 2007010812 2007010999 2007011023 2010010114 2010010216 2010010317 2010010410 2010010506 2015010649 2015010722 2015010812 2015010999 2015011023
设计代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class Temperature { public static class TempMapper extends Mapper <LongWritable, Text, Text, IntWritable> { public void map (LongWritable key, Text value, Context context) throws IOException, InterruptedException { System.out.print("Before Mapper:" + key + "," + value); String line = value.toString(); String year = line.substring(0 , 4 ); int temperature = Integer.parseInt(line.substring(8 )); context.write(new Text (year), new IntWritable (temperature)); System.out.println(" ==> After Mapper:" + new Text (year) + "," + new IntWritable (temperature)); } } public static class TempReducer extends Reducer <Text, IntWritable, Text, IntWritable> { public void reduce (Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int maxValue = Integer.MIN_VALUE; StringBuffer sb = new StringBuffer (); for (IntWritable value : values) { maxValue = Math.max(maxValue, value.get()); sb.append(value).append("," ); } System.out.print("Before Reduce:" + key + "," + sb.toString()); context.write(key, new IntWritable (maxValue)); System.out.println(" ==> After Reduce:" + key + "," + maxValue); } } public static void main (String[] args) throws Exception { Configuration conf = new Configuration (); Job job = Job.getInstance(conf, "Temperature" ); job.setJarByClass(Temperature.class); job.setMapperClass(TempMapper.class); job.setReducerClass(TempReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path ("hdfs://localhost:8020/Temperature/input/input_temperature.txt" )); FileOutputFormat.setOutputPath(job, new Path ("hdfs://localhost:8020/Temperature/output" )); System.exit(job.waitForCompletion(true ) ? 0 : 1 ); } }
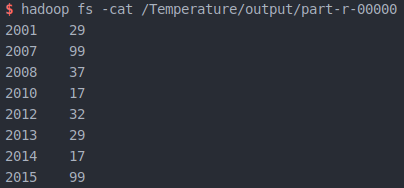
实验结果
运行程序,成功后可以看到在 /Temperature/output/ 下多出两个文件
其中第二个文件里为运行完成后的结果
统计每年最高气温完成!
数据去重 实验原理
“数据去重” 主要是为了掌握和利用并行化思想来对数据进行有意义的筛选。统计大数据集上的数据种类个数、从网站日志中计算访问地等这些看似庞杂的任务都会涉及数据去重。
数据去重的最终目标是让原始数据中出现次数超过一次的数据在输出文件中只出现一次。在 MapReduce 流程中,map 的输出 <key,value> 经过 shuffle 过程聚集成 <key,value-list> 后交给 reduce。我们自然而然会想到将同一个数据的所有记录都交给一台 reduce 机器,无论这个数据出现多少次,只要在最终结果中输出一次就可以了。具体就是 reduce 的输入应该以数据作为 key,而对 value-list 则没有要求(可以设置为空)。当 reduce 接收到一个 <key,value-list> 时就直接将输入的 key 复制到输出的 key 中,并将 value 设置成空值,然后输出 <key,value>。
实验数据
现有一个某电商网站的数据文件,名为 buyer_favorite1,记录了用户收藏的商品以及收藏的日期,文件 buyer_favorite1 中包含(用户 id,商品 id,收藏日期)三个字段,数据内容以 \t 分割,由于数据很大,所以为了方便统计我们只截取它的一部分数据,内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 user_id product_id date10181 1000481 2010 -04 -04 16 :54 :31 20001 1001597 2010 -04 -07 15 :07 :52 20001 1001560 2010 -04 -07 15 :08 :27 20042 1001368 2010 -04 -08 08 :20 :30 20067 1002061 2010 -04 -08 16 :45 :33 20056 1003289 2010 -04 -12 10 :50 :55 20056 1003290 2010 -04 -12 11 :57 :35 20056 1003292 2010 -04 -12 12 :05 :29 20054 1002420 2010 -04 -14 15 :24 :12 20055 1001679 2010 -04 -14 19 :46 :04 20054 1010675 2010 -04 -14 15 :23 :53 20054 1002429 2010 -04 -14 17 :52 :45 20076 1002427 2010 -04 -14 19 :35 :39 20054 1003326 2010 -04 -20 12 :54 :44 20056 1002420 2010 -04 -15 11 :24 :49 20064 1002422 2010 -04 -15 11 :35 :54 20056 1003066 2010 -04 -15 11 :43 :01 20056 1003055 2010 -04 -15 11 :43 :06 20056 1010183 2010 -04 -15 11 :45 :24 20056 1002422 2010 -04 -15 11 :45 :49 20056 1003100 2010 -04 -15 11 :45 :54 20056 1003094 2010 -04 -15 11 :45 :57 20056 1003064 2010 -04 -15 11 :46 :04 20056 1010178 2010 -04 -15 16 :15 :20 20076 1003101 2010 -04 -15 16 :37 :27 20076 1003103 2010 -04 -15 16 :37 :05 20076 1003100 2010 -04 -15 16 :37 :18 20076 1003066 2010 -04 -15 16 :37 :31 20054 1003103 2010 -04 -15 16 :40 :14 20054 1003100 2010 -04 -15 16 :40 :16
将其上传到 HDFS 中,路径为 /Filter/input
要求用 Java 编写 MapReduce 程序,根据商品 id 进行去重,统计用户收藏商品中都有哪些商品被收藏。
实验源码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;import java.io.IOException;public class Filter { public static class Map extends Mapper <Object, Text, Text, NullWritable> { private static Text newKey = new Text (); public void map (Object key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); System.out.println("line is " + line); if (line != null ) { String arr[] = line.split(" " ); System.out.println("a[1] is " + arr[1 ]); newKey.set(arr[1 ]); context.write(newKey, NullWritable.get()); System.out.println("the new key is " + newKey); } } } public static class Reduce extends Reducer <Text, NullWritable, Text, NullWritable> { public void reduce (Text key, Iterable<NullWritable> values, Context context) throws IOException,InterruptedException { context.write(key, NullWritable.get()); } } public static void main (String[] args) throws IOException, ClassNotFoundException, InterruptedException{ Configuration conf = new Configuration (); Job job = Job.getInstance(conf, "Filter" ); job.setJarByClass(Filter.class); job.setMapperClass(Map.class); job.setReducerClass(Reduce.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(NullWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); FileInputFormat.addInputPath(job ,new Path ("hdfs://localhost:8020/Filter/input/buyer_favorite.txt" )); FileOutputFormat.setOutputPath(job, new Path ("hdfs://localhost:8020/Filter/output" )); System.exit(job.waitForCompletion(true ) ? 0 : 1 ); } }
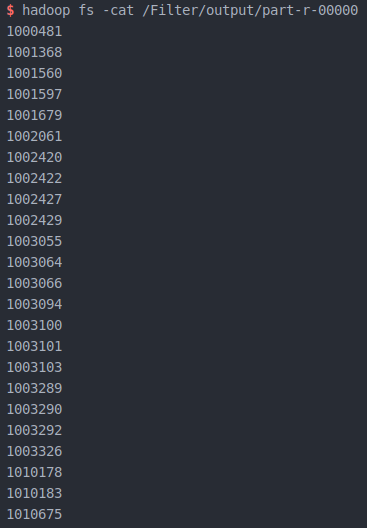
实验结果
运行程序,成功后可以看到在 /Filter/output/ 下多出两个文件
其中第二个文件里为运行完成后的结果
数据去重完成!
日志分析:分析非结构化文件 根据 tomcat 日志计算 url 访问情况
要求:区别统计 GET 和 POST URL 访问量
结果为:访问方式、URL、访问量
测试数据集:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 196.168.2.1 - - [03/Jul/2014:23:36:38 +0800] "GET /course/detail/3.htm HTTP/1.0" 200 38435 0.038 182.131.89.195 - - [03/Jul/2014:23:37:43 +0800] "GET /html/notes/20140617/888.html HTTP/1.0" 301 - 0.000 196.168.2.1 - - [03/Jul/2014:23:38:27 +0800] "POST /service/notes/addViewTimes_23.htm HTTP/1.0" 200 2 0.003 196.168.2.1 - - [03/Jul/2014:23:39:03 +0800] "GET /html/notes/20140617/779.html HTTP/1.0" 200 69539 0.046 196.168.2.1 - - [03/Jul/2014:23:43:00 +0800] "GET /html/notes/20140318/24.html HTTP/1.0" 200 67171 0.049 196.168.2.1 - - [03/Jul/2014:23:43:59 +0800] "POST /service/notes/addViewTimes_779.htm HTTP/1.0" 200 1 0.003 196.168.2.1 - - [03/Jul/2014:23:45:51 +0800] "GET /html/notes/20140617/888.html HTTP/1.0" 200 70044 0.060 196.168.2.1 - - [03/Jul/2014:23:46:17 +0800] "GET /course/list/73.htm HTTP/1.0" 200 12125 0.010 196.168.2.1 - - [03/Jul/2014:23:46:58 +0800] "GET /html/notes/20140609/542.html HTTP/1.0" 200 94971 0.077 196.168.2.1 - - [03/Jul/2014:23:48:31 +0800] "POST /service/notes/addViewTimes_24.htm HTTP/1.0" 200 2 0.003 196.168.2.1 - - [03/Jul/2014:23:48:34 +0800] "POST /service/notes/addViewTimes_542.htm HTTP/1.0" 200 2 0.003 196.168.2.1 - - [03/Jul/2014:23:49:31 +0800] "GET /notes/index-top-3.htm HTTP/1.0" 200 53494 0.041 196.168.2.1 - - [03/Jul/2014:23:50:55 +0800] "GET /html/notes/20140609/544.html HTTP/1.0" 200 183694 0.076 196.168.2.1 - - [03/Jul/2014:23:53:32 +0800] "POST /service/notes/addViewTimes_544.htm HTTP/1.0" 200 2 0.004 196.168.2.1 - - [03/Jul/2014:23:54:53 +0800] "GET /service/notes/addViewTimes_900.htm HTTP/1.0" 200 151770 0.054 196.168.2.1 - - [03/Jul/2014:23:57:42 +0800] "GET /html/notes/20140620/872.html HTTP/1.0" 200 52373 0.034 196.168.2.1 - - [03/Jul/2014:23:58:17 +0800] "POST /service/notes/addViewTimes_900.htm HTTP/1.0" 200 2 0.003 196.168.2.1 - - [03/Jul/2014:23:58:51 +0800] "GET /html/notes/20140617/888.html HTTP/1.0" 200 70044 0.057 186.76.76.76 - - [03/Jul/2014:23:48:34 +0800] "POST /service/notes/addViewTimes_542.htm HTTP/1.0" 200 2 0.003 186.76.76.76 - - [03/Jul/2014:23:46:17 +0800] "GET /course/list/73.htm HTTP/1.0" 200 12125 0.010 8.8.8.8 - - [03/Jul/2014:23:46:58 +0800] "GET /html/notes/20140609/542.html HTTP/1.0" 200 94971 0.077
将其上传到 HDFS 中,路径为 /LogAnalyze/input
由于 Tomcat 日志是不规则的,需要先过滤清洗数据。这里使用 MapReduce 进行操作。
代码实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class LogAnalyze { public static class LogMapper extends Mapper <LongWritable, Text, Text , IntWritable> { private IntWritable val = new IntWritable (1 ); public void map (LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString().trim(); String tmp = handlerLog(line); if (tmp.length() > 0 ) { context.write(new Text (tmp), val); } } private String handlerLog (String line) { String result = "" ; try { if (line.length() > 20 ) { if (line.indexOf("GET" ) > 0 ) { result = line.substring(line.indexOf("GET" ), line.indexOf("HTTP/1.0" )).trim(); } else if (line.indexOf("POST" ) > 0 ) { result = line.substring(line.indexOf("POST" ), line.indexOf("HTTP/1.0" )).trim(); } } } catch (Exception e) { System.out.println(line); } return result; } } public static class LogReducer extends Reducer <Text, IntWritable, Text, IntWritable> { public void reduce (Text key, Iterable<IntWritable> values, Context context) throws IOException,InterruptedException { int sum = 0 ; for (IntWritable val : values) { sum += val.get(); } context.write(key, new IntWritable (sum)); } } public static void main (String[] args) throws Exception { Configuration conf = new Configuration (); Job job = Job.getInstance(conf, "Log Analyze" ); job.setJarByClass(LogAnalyze.class); job.setMapperClass(LogMapper.class); job.setReducerClass(LogReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path ("hdfs://localhost:8020/LogAnalyze/input/data.txt" )); FileOutputFormat.setOutputPath(job, new Path ("hdfs://localhost:8020/LogAnalyze/output" )); System.exit(job.waitForCompletion(true ) ? 0 : 1 ); } }
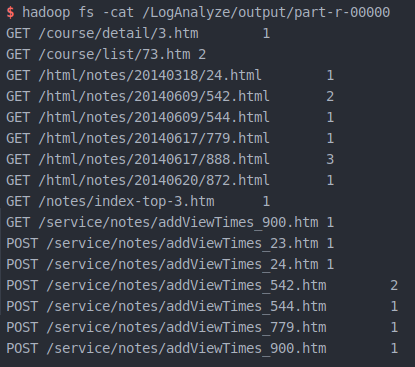
分析结果
Log 分析完成!