RDD 简介 RDD,全称 Resilient Distributed Datasets(弹性分布式数据集),是 Spark 最为核心的概念,是 Spark 对数据的抽象。
RDD 是分布式的元素集合,每个 RDD 只支持读操作,且每个 RDD 都被分为多个分区存储到集群的不同节点上。除此之外,RDD 还允许用户显示的指定数据存储到内存和磁盘中。
对 RDD 的操作,从类型上也比较简单,包括:创建 RDD、转化已有的 RDD 以及在已有 RDD 的基础上进行求值。
RDD 编程练习 flatMap flatMap() 接收一个函数作为参数,该函数将每个元素转为一个列表,最终 flatMap() 并不是返回由上述列表作为元素组成的 RDD,而是返回一个包含每个列表所有元素的 RDD
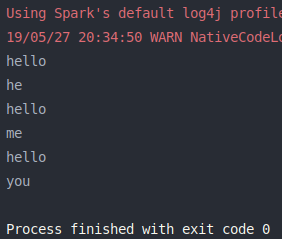
flatMap() 练习代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import org.apache.log4j.{Level , Logger }import org.apache.spark.{SparkConf , SparkContext }object flatMap def main Array [String ]): Unit = { val conf = new SparkConf ().setMaster("local[2]" ).setAppName("RDDFlatMap" ) Logger .getLogger("org.apache.spark" ).setLevel(Level .OFF ) val sc = new SparkContext (conf) transformationOps(sc) sc.stop() } def transformationOps SparkContext ): Unit = { val list = List ("hello you" , "hello he" , "hello me" ) val listRDD = sc.parallelize(list) val wordsRDD = listRDD.flatMap(line => line.split(" " )) wordsRDD.foreach(println) } }
结果如下图:
sample sample() 采样变换根据给定的随机种子,从 RDD 中随机地按指定比例选一部分记录,创建新的 RDD。
语法
1 def sample Boolean , fraction: Double , seed: Long = Utils .random.nextLong): RDD [T ]
参数 withReplacement: Boolean, True 表示进行替换采样,False 表示进行非替换采样fraction: Double, 在 0~1 之间的一个浮点值,表示要采样的记录在全体记录中的比例seed: 随机种子
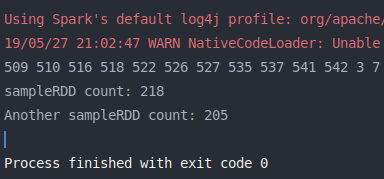
sample() 练习代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import org.apache.log4j.{Level , Logger }import org.apache.spark.{SparkConf , SparkContext }object sample def main Array [String ]): Unit = { val conf = new SparkConf ().setMaster("local[2]" ).setAppName(sample.getClass.getSimpleName) Logger .getLogger("org.apache.spark" ).setLevel(Level .OFF ) val sc = new SparkContext (conf) transformationOps(sc) sc.stop() } def transformationOps SparkContext ): Unit = { val list = 1 to 1000 val listRDD = sc.parallelize(list) val sampleRDD = listRDD.sample(false , 0.2 ) sampleRDD.foreach(num => print(num + " " )) println println("sampleRDD count: " + sampleRDD.count()) println("Another sampleRDD count: " + sc.parallelize(list).sample(false , 0.2 ).count()) } }
结果如下图:
union union() 合并变换将两个 RDD 合并为一个新的 RDD,重复的记录不会被剔除。
语法
1 def union RDD [T ]): RDD [T ]
参数 other: 第二个 RDD
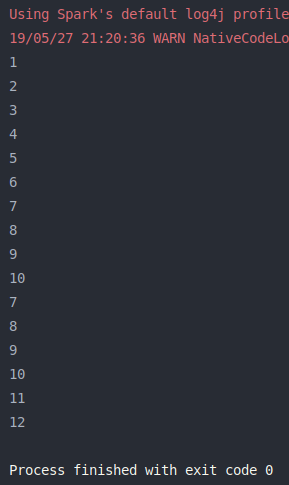
union() 练习代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import org.apache.log4j.{Level , Logger }import org.apache.spark.{SparkConf , SparkContext }object union def main Array [String ]): Unit = { val conf = new SparkConf ().setMaster("local[2]" ).setAppName(union.getClass.getSimpleName) Logger .getLogger("org.apache.spark" ).setLevel(Level .OFF ) val sc = new SparkContext (conf) transformationOps(sc) sc.stop() } def transformationOps SparkContext ): Unit = { val list1 = List (1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 ) val list2 = List (7 , 8 , 9 , 10 , 11 , 12 ) val listRDD1 = sc.parallelize(list1) val listRDD2 = sc.parallelize(list2) val unionRDD = listRDD1.union(listRDD2) unionRDD.foreach(println) } }
结果如下图:
groupByKey groupByKey() 将 RDD 中每个键的值分组为单个序列。
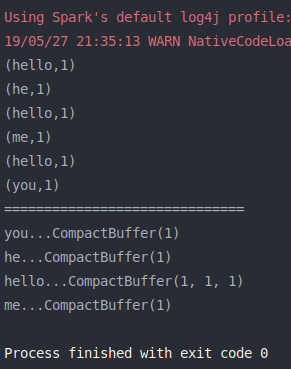
groupByKey() 练习代码:
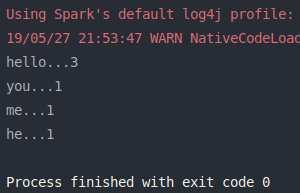
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import org.apache.log4j.{Level , Logger }import org.apache.spark.{SparkConf , SparkContext }object groupByKey def main Array [String ]): Unit = { val conf = new SparkConf ().setMaster("local[2]" ).setAppName(groupByKey.getClass.getSimpleName) Logger .getLogger("org.apache.spark" ).setLevel(Level .OFF ) val sc = new SparkContext (conf) transformationOps(sc) sc.stop() def transformationOps SparkContext ): Unit = { val list = List ("hello you" , "hello he" , "hello me" ) val listRDD = sc.parallelize(list) val wordsRDD = listRDD.flatMap(line => line.split(" " )) val pairsRDD = wordsRDD.map(word => (word, 1 )) pairsRDD.foreach(println) val gbkRDD = pairsRDD.groupByKey() println("==============================" ) gbkRDD.foreach(t => println(t._1 + "..." + t._2)) } } }
结果如下图:
reduceByKey 与 groupByKey() 类似,却有不同。
如 (a,1), (a,2), (b,1), (b,2),groupByKey() 产生中间结果为 ((a,1), (a,2)), ((b,1), (b,2)),reduceByKey() 为 (a,3), (b,3)。
reduceByKey() 主要作用是聚合,groupByKey() 主要作用是分组
reduceByKey() 练习代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import org.apache.log4j.{Level , Logger }import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf , SparkContext }object reduceByKey def main Array [String ]): Unit = { val conf = new SparkConf ().setMaster("local[2]" ).setAppName(reduceByKey.getClass.getSimpleName) Logger .getLogger("org.apache.spark" ).setLevel(Level .OFF ) val sc = new SparkContext (conf) transformationOps(sc) sc.stop() } def transformationOps SparkContext ): Unit = { val list = List ("hello you" , "hello he" , "hello me" ) val listRDD = sc.parallelize(list) val wordsRDD = listRDD.flatMap(line => line.split(" " )) val pairsRDD: RDD [(String , Int )] = wordsRDD.map(word => (word, 1 )) val retRDD: RDD [(String , Int )] = pairsRDD.reduceByKey((v1, v2) => v1 + v2) retRDD.foreach(t => println(t._1 + "..." + t._2)) } }
结果如下图:
sortByKey sortByKey([ascending], [numTasks])
sortByKey() 作用于 Key-Value 形式的 RDD,并对 Key 进行排序。
[ascending] 升序,默认为 true,即升序
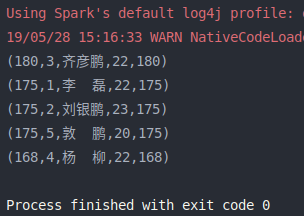
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 import org.apache.log4j.{Level , Logger }import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf , SparkContext }object sortByKey def main Array [String ]): Unit = { val conf = new SparkConf ().setMaster("local[2]" ).setAppName(sortByKey.getClass.getSimpleName) Logger .getLogger("org.apache.spark" ).setLevel(Level .OFF ) val sc = new SparkContext (conf) transformationOps(sc) sc.stop() } def transformationOps SparkContext ): Unit = { val list = List ( "1,李 磊,22,175" , "2,刘银鹏,23,175" , "3,齐彦鹏,22,180" , "4,杨 柳,22,168" , "5,敦 鹏,20,175" ) val listRDD:RDD [String ] = sc.parallelize(list) val heightRDD:RDD [(String , String )] = listRDD.map(line => { val fields = line.split("," ) (fields(3 ), line) }) val retRDD:RDD [(String , String )] = heightRDD.sortByKey(ascending = false , numPartitions = 1 ) retRDD.foreach(println) } }
combineByKey 与 aggregeteByKey 下面的代码分别使用 aggregateByKey() 和 combineByKey() 来模拟 groupByKey() 和 reduceBykey()
使用 aggregateByKey 模拟 groupByKey
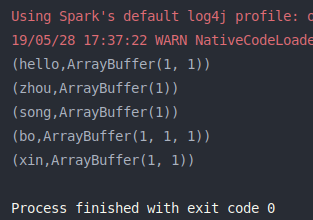
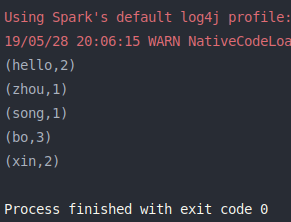
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import org.apache.log4j.{Level , Logger }import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf , SparkContext }import scala.collection.mutable.ArrayBuffer object aggregateByKey_1 def main Array [String ]): Unit = { val conf = new SparkConf ().setMaster("local[2]" ).setAppName(aggregateByKey_1.getClass.getSimpleName) Logger .getLogger("org.apache.spark" ).setLevel(Level .OFF ) val sc = new SparkContext (conf) aggregateByKey2GroupByKey(sc) sc.stop() def aggregateByKey2GroupByKey SparkContext ): Unit = { val list = List ("hello bo bo" , "zhou xin xin" , "hello song bo" ) val lineRDD = sc.parallelize(list) val wordsRDD = lineRDD.flatMap(line => line.split(" " )) val pairsRDD = wordsRDD.map(word => (word, 1 )) val retRDD: RDD [(String , ArrayBuffer [Int ])] = pairsRDD.aggregateByKey(ArrayBuffer [Int ]())( (part, num) => { part.append(num) part }, (part1, part2) => { part1.++=(part2) part1 } ) retRDD.foreach(println) } } }
运行结果:
使用 aggregateByKey 模拟 reduceByKey
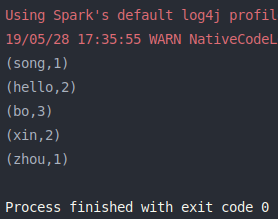
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 import org.apache.log4j.{Level , Logger }import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf , SparkContext }object aggregateByKey_2 def main Array [String ]): Unit = { val conf = new SparkConf ().setMaster("local[2]" ).setAppName(aggregateByKey_2.getClass.getSimpleName) Logger .getLogger("org.apache.spark" ).setLevel(Level .OFF ) val sc = new SparkContext (conf) aggregateByKey2ReduceByKey(sc) sc.stop() def aggregateByKey2ReduceByKey SparkContext ): Unit = { val list = List ("hello bo bo" , "zhou xin xin" , "hello song bo" ) val lineRDD = sc.parallelize(list) val wordsRDD = lineRDD.flatMap(line => line.split(" " )) val pairsRDD = wordsRDD.map(word => (word, 1 )) val retRDD: RDD [(String , Int )] = pairsRDD.aggregateByKey(0 )( (partNum, num) => partNum + num, (partNum1, partNum2) => partNum1 + partNum2 ) retRDD.foreach(println) } } }
运行结果:
使用 combineByKey 模拟 reduceByKey
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 import org.apache.log4j.{Level , Logger }import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf , SparkContext }object combineByKey_1 def main Array [String ]): Unit = { val conf = new SparkConf ().setMaster("local[2]" ).setAppName(combineByKey_1.getClass.getSimpleName) Logger .getLogger("org.apache.spark" ).setLevel(Level .OFF ) val sc = new SparkContext (conf) combineByKey2ReduceByKey(sc) sc.stop() def combineByKey2ReduceByKey SparkContext ): Unit = { val list = List ("hello bo bo" , "zhou xin xin" , "hello song bo" ) val lineRDD = sc.parallelize(list) val wordsRDD = lineRDD.flatMap(line => line.split(" " )) val pairsRDD = wordsRDD.map(word => (word, 1 )) val retRDD: RDD [(String , Int )] = pairsRDD.combineByKey(createCombiner1, mergeValue1, mergeCombiners1) retRDD.foreach(println) } def createCombiner1 Int ): Int = { num } def mergeValue1 Int , localNum2: Int ): Int = { localNum1 + localNum2 } def mergeCombiners1 Int , anotherPartitionNum2: Int ): Int = { thisPartitionNum1 + anotherPartitionNum2 } } }
运行结果:
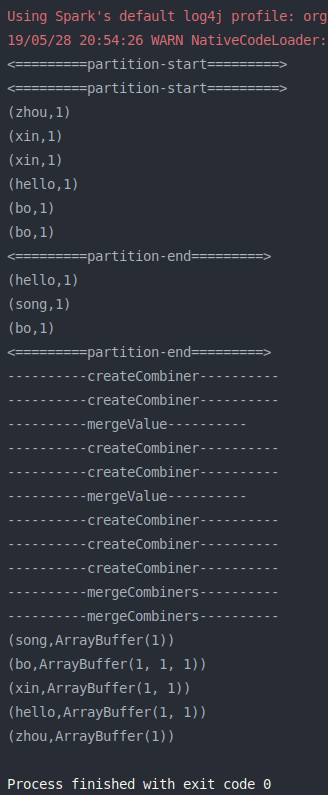
使用 combineByKey 模拟 groupByKey
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 import org.apache.log4j.{Level , Logger }import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf , SparkContext }import scala.collection.mutable.ArrayBuffer object combineByKey_2 def main Array [String ]): Unit = { val conf = new SparkConf ().setMaster("local[2]" ).setAppName(combineByKey_2.getClass.getSimpleName) Logger .getLogger("org.apache.spark" ).setLevel(Level .OFF ) val sc = new SparkContext (conf) combineByKey2GroupByKey(sc) sc.stop() def combineByKey2GroupByKey SparkContext ): Unit = { val list = List ("hello bo bo" , "zhou xin xin" , "hello song bo" ) val lineRDD = sc.parallelize(list) val wordsRDD = lineRDD.flatMap(line => line.split(" " )) val pairsRDD = wordsRDD.map(word => (word, 1 )) pairsRDD.foreachPartition(partition => { println("<=========partition-start=========>" ) partition.foreach(println) println("<=========partition-end=========>" ) }) val gbkRDD: RDD [(String , ArrayBuffer [Int ])] = pairsRDD.combineByKey(createCombiner, mergeValue, mergeCombiners) gbkRDD.foreach(println) } def createCombiner Int ): ArrayBuffer [Int ] = { println("----------createCombiner----------" ) ArrayBuffer [Int ](num) } def mergeValue ArrayBuffer [Int ], num: Int ): ArrayBuffer [Int ] = { println("----------mergeValue----------" ) ab.append(num) ab } def mergeCombiners ArrayBuffer [Int ], ab2: ArrayBuffer [Int ]): ArrayBuffer [Int ] = { println("----------mergeCombiners----------" ) ab1 ++= ab2 ab1 } } }