Spark —— 淘宝双 11 数据分析
问题定义
实验内容
使用 Spark 对数据进行处理,并分析双十一的用户交易等信息,用 Scala 语言进行程序编写,最后将处理的数据结果使用 Echarts 进行可视化。
实验环境以及使用的相关应用:
- Spark 2.4.3
- Scala 2.12
- Tomcat 9.0.20
- 可视化工具:ECharts
- Java 包:fastjson
- 系统环境:macOS Mojave 10.14.5
数据集
本案列主要分析淘宝双十一的数据,数据集是淘宝 2015 年双十一前 6 个月(包含双十一)的交易数据,数据集 user_log.csv,是记录了用户的行为的日志文件。
日志 user_log.csv 的字段定义如下:
| 序号 | 字段 | 定义 |
|---|---|---|
| 0 | user_id | 买家 id |
| 1 | item_id | 商品 id |
| 2 | cat_id | 商品类别 id |
| 3 | merchant_id | 卖家 id |
| 4 | brand_id | 品牌 id |
| 5 | month | 交易时间:月 |
| 6 | day | 交易事件:日 |
| 7 | action | 行为,取值范围 {0,1,2,3},0 表示点击,1 表示加入购物车,2 表示购买,3 表示关注商品 |
| 8 | age_range | 买家年龄分段:1 表示年龄 <18;2 表示年龄在 [18,24];3 表示年龄在 [25,29];4 表示年龄在 [30,34];5 表示年龄在 [35,39];6 表示年龄在 [40,49];7 和 8 表示年龄 >=50;0 和 NULL 则表示未知 |
| 9 | gender | 性别:0 表示女性,1 表示男性,2 和 NULL 表示未知 |
| 10 | province | 收货地址省份 |
前五条记录样例:
1 | user_id,item_id,cat_id,merchant_id,brand_id,month,day,action,age_range,gender,province |
SparkRDD 实验过程及其结果
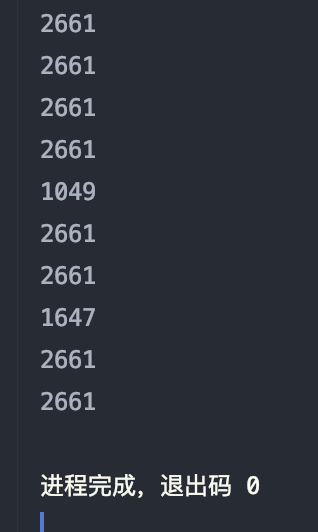
实验一:查看日志前 10 个交易日志的商品品牌
分析:使用 take() 函数,取去掉首行后的前 10 行数据,按条件为 brand_id 的项进行筛选,并逐个输出
- 使用
take()函数取出去掉首行后的前 10 行数据 - 进行 map 操作,将数据处理成
($商品品牌)样式 - 输出 map 后的结果
核心代码如下:
1 | def transformationOps(sc: SparkContext): Unit = { |
结果如图:
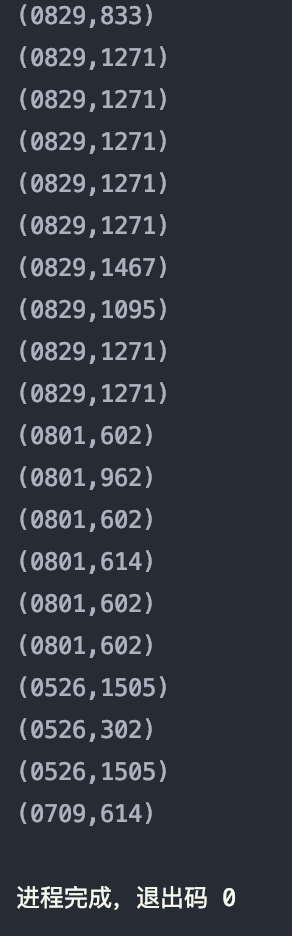
实验二:查询前 20 个交易日志中购买商品时的时间和商品的种类
分析:使用 take() 函数,取去掉首行后的前 20 行数据,按条件为 month, day, cat_id 的项进行筛选,并逐个输出。(这里将 month 和 day 合并为一个字符串)
- 使用
take()函数取出去掉首行后的前 20 行数据 - 进行 map 操作,将数据处理成
($日期, $商品种类)样式 - 输出 map 后的结果
核心代码如下:
1 | def transformationOps(sc: SparkContext): Unit = { |
结果如图:
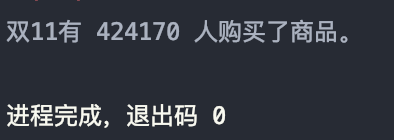
实验三:查询双十一那天有多少人购买了商品
分析:
- 首先进行 map 操作,将数据处理成
($日期, $用户ID, $用户行为)样式 - 然后使用
filter()函数过滤出 11 月 11 日所有用户行为为购买的条目,具体为日期month == 11, day == 11,行为action == 2 - 考虑到单个用户可能购买多个商品,所以需要去重,使用
distinct()函数去重 - 最后使用
count()函数计数并输出
核心代码如下:
1 | def transformationOps(sc: SparkContext): Unit = { |
结果如图:
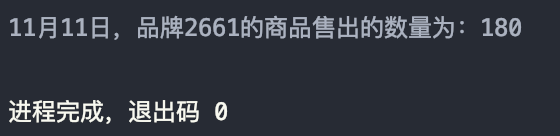
实验四:取给定时间和给定品牌,求当天购买的此品牌商品的数量
分析:
- 首先进行 map 操作,将数据处理成
($品牌ID, $日期, $用户行为)样式 - 然后使用
filter()函数过滤出 11 月 11 日品牌 2661 中用户行为为购买的条目,具体为日期month == 11, day == 11,品牌 IDbrand_id == 2661,行为action == 2 - 使用
count()函数计数并输出
核心代码如下:
1 | def transformationOps(sc: SparkContext): Unit = { |
结果如图:
实验五:查询有多少用户在双十一点击了该店
分析:
- 首先进行 map 操作,将数据处理成
($用户ID, $卖家ID, $日期, $用户行为)样式 - 然后使用
filter()函数过滤出 11 月 11 日店铺 2882 中用户行为为点击的用户,具体为日期month == 11, day == 11,卖家 IDmerchant_id == 2882,行为action == 0 - 考虑到每个用户可能多次点击同一店铺,所以需要去重,使用
distinct()函数。
核心代码如下:
1 | def transformationOps(sc: SparkContext): Unit = { |
结果如图:
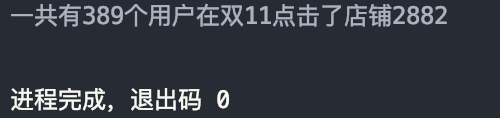
实验六:查询双十一那天女性购买商品的数量
分析:统计同时满足日期 month == 11, day == 11,行为 action == 2,性别 gender == 0 的个数。
- 首先进行 map 操作,将数据处理成
(($用户ID, $日期, $用户行为), 1)样式 - 然后使用
filter()函数过滤出 11 月 11 日用户行为为购买的用户,具体为日期month == 11, day == 11,行为action == 2 - 然后使用
reduceByKey()统计所有用户的购买量,然后使用filter()筛选出大于 5 次的用户,并逐个输出
核心代码如下:
1 | def transformationOps(sc: SparkContext): Unit = { |
结果如图:

实验七:查询双十一那天男性购买商品的数量
分析:
- 首先进行 map 操作,将数据处理成
($日期, $用户行为, $性别)样式 - 然后使用
filter()函数过滤出 11 月 11 日用户行为为购买的男性用户,具体为日期month == 11, day == 11,行为action == 2,性别gender == 1 - 然后使用
count()函数统计所有过滤后的数据量,并输出
核心代码如下:
1 | def transformationOps(sc: SparkContext): Unit = { |
结果如图:

实验八:查询某一天在该网站购买商品超过 5 次的用户 ID
分析:
- 首先进行 map 操作,将数据处理成
(($用户ID, $日期, $用户行为), 1)样式 - 然后使用
filter()函数过滤出 11 月 11 日用户行为为购买的用户,具体为日期month == 11, day == 11,行为action == 2 - 然后使用
reduceByKey()统计所有用户的购买量,然后使用filter()筛选出大于 5 次的用户,并逐个输出
核心代码如下:
1 | def transformationOps(sc: SparkContext): Unit = { |
结果如图:
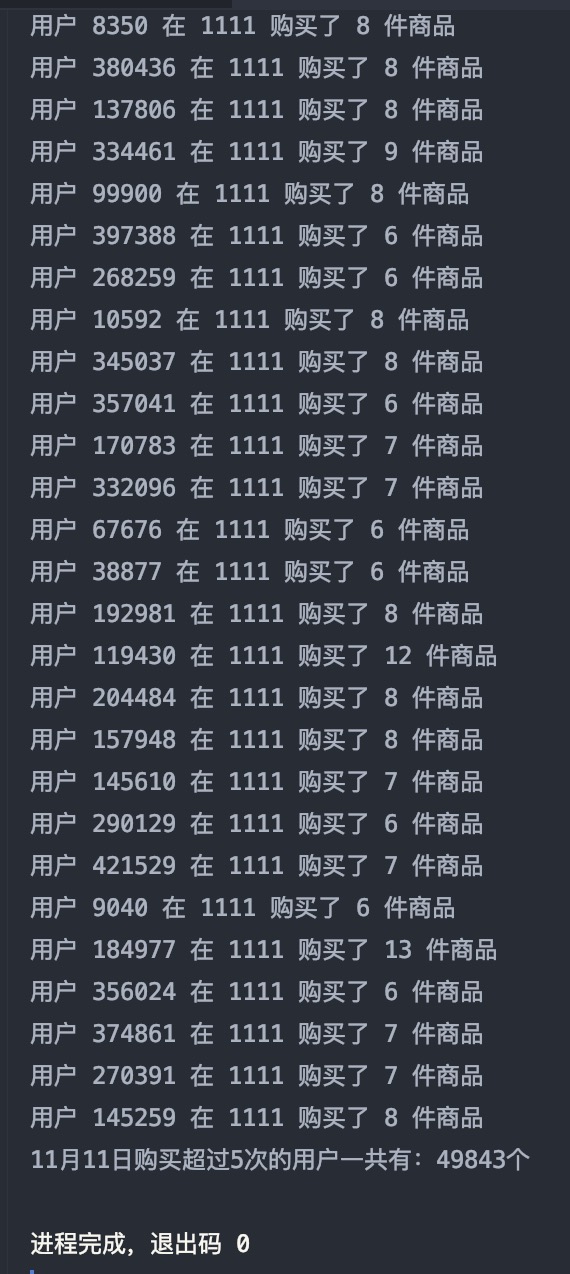
使用 ECharts 进行可视化
ECharts,一个使用 JavaScript 实现的开源可视化库,可以流畅的运行在 PC 和移动设备上,兼容当前绝大部分浏览器(IE8/9/10/11,Chrome,Firefox,Safari 等),底层依赖轻量级的矢量图形库 ZRender,提供直观,交互丰富,可高度个性化定制的数据可视化图表。
首先使用 SparkRDD 处理我们需要的数据,使用阿里巴巴的 Java 库 fastjson,将 SparkRDD 输出的数据转换成 JSON 格式的文档。然后使用 Tomcat 搭建 JSP 服务,用 jQuery 将 *.json 文件内的数据导入到 ECharts,最后呈现数据。
可视化实验一:双十一所有买家消费行为比例
数据处理
分析:
- 首先进行 map 操作,将数据处理成
($日期, $用户行为)样式 - 然后使用
filter()函数确定时间为 11 月 11 日,具体为日期month == 11, day == 11 - 使用
map()函数将数据处理为($用户行为, 1) - 使用
reduceByKey()计算出每个用户行为对应的条目数 - 将结果转换成 JSON 格式文件,并输出处理结果
数据处理核心代码如下:
1 | def transformationOps(sc: SparkContext): Unit = { |
转换成 JSON 文件
编写 toJSON_Pie() 函数,将 SparkRDD 处理的结果转换成 JSON 格式的文件,用于生成饼状图
- 使用阿里巴巴 Java 库
fastjson,新建一个JSONObject对象 - 新建一个数组准备存放绘制 EChart 饼状图要求的
{"name":"","value":""}对 - 使用循环,按行读取,放入 SparkRDD 处理的结果
- 导出,保存
函数代码如下:
1 | def toJSON_Pie(data: Array[(String, Int)], sc: SparkContext): Unit = { |
导出后的文件为 Spark 处理的文件,名称为 part-00000,需要手动将其加上 json 后缀为 part-00000.json
由于原始数据中代表用户行为的数据为 0~3,数字对可视化呈现不直观,所以手动更改了 json 文件的对应内容
part-00000.json 文件内容为:
1 | { |
可视化呈现
使用 Tomcat 搭建本地 Java Web Server,编写 jsp 网页,将 *.json 文件导入,使用 ECharts 呈现
根据 ECharts 官方文档:异步数据加载和更新,使用 jQuery 工具将 json 文件导入
核心代码如下:
1 | var myChart = echarts.init(document.getElementById('main'), 'shine'); |
可视化结果如图所示:
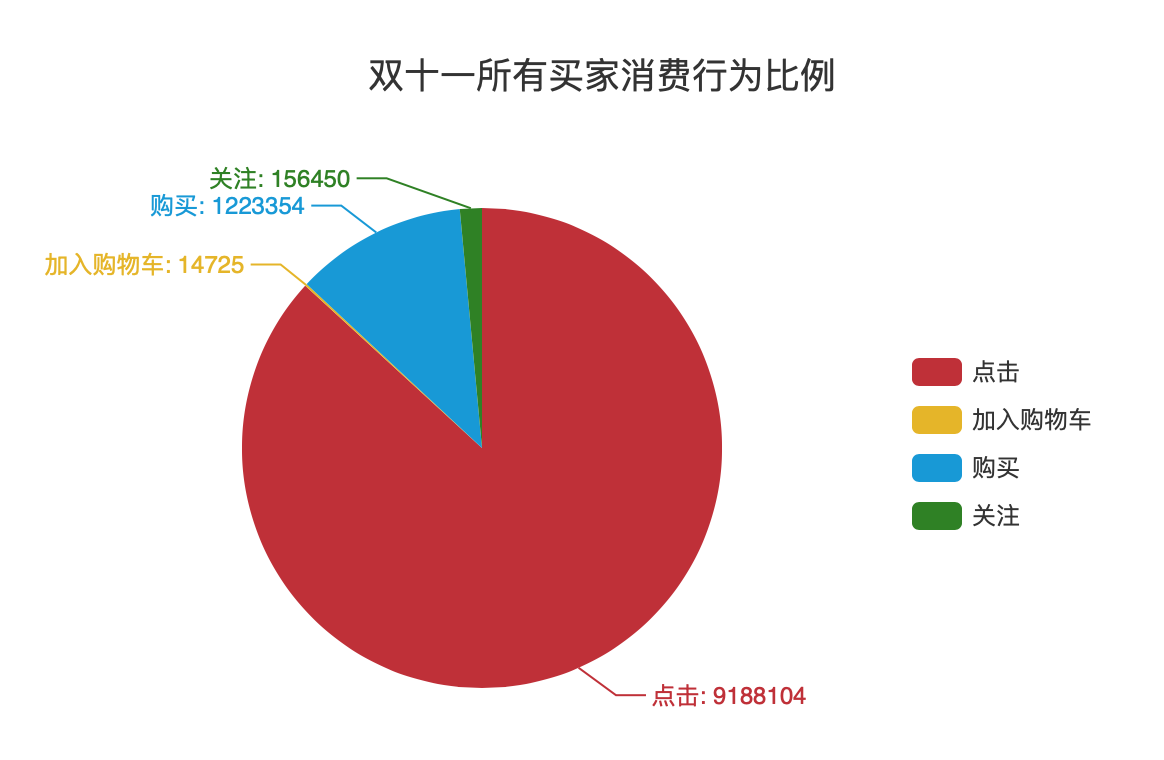
可视化实验二:双十一当天销量前十的商品类别
数据处理
分析:
- 首先进行 map 操作,将数据处理成
($日期, $商品类别, $用户行为)样式 - 使用
filter()函数确定时间为 11 月 11 日,用户行为为购买的数据,具体为日期month == 11, day == 11,用户行为action == 2 - 使用
map()函数将数据处理为($商品类别, 1) - 使用
reduceByKey()计算出每个商品类别对应的条目数 - 使用
sortBy()按条目数量降序排序 - 使用
take()取前 10 个数据,然后将结果转换成 JSON 格式文件,并输出处理结果
数据处理核心代码如下:
1 | def transformationOps(sc: SparkContext): Unit = { |
转换成 JSON 文件
编写 toJSON_Bar() 函数,将 SparkRDD 处理的结果转换成 JSON 格式的文件,用于生成柱状图
- 使用阿里巴巴 Java 库
fastjson,新建一个JSONObject对象 - 新建两个数组准备存放绘制 EChart 柱状图要求的数据
- 使用循环,按行读取,放入 SparkRDD 处理的结果
- 导出,保存
函数代码如下:
1 | def toJSON_Bar(data: Array[(String, Int)], sc: SparkContext): Unit = { |
导出后的文件为 Spark 处理的文件,名称为 part-00000,需要手动将其加上 json 后缀为 part-00000.json
part-00000.json 文件内容为:
1 | { |
其中,key 表示商品种类,value 表示对应商品种类的销量
可视化呈现
使用 Tomcat 搭建本地 Java Web Server,编写 jsp 网页,将 *.json 文件导入,使用 ECharts 呈现
根据 ECharts 官方文档:异步数据加载和更新,使用 jQuery 工具将 json 文件导入
核心代码如下:
1 | // 基于准备好的dom,初始化echarts实例 |
可视化结果如图所示:
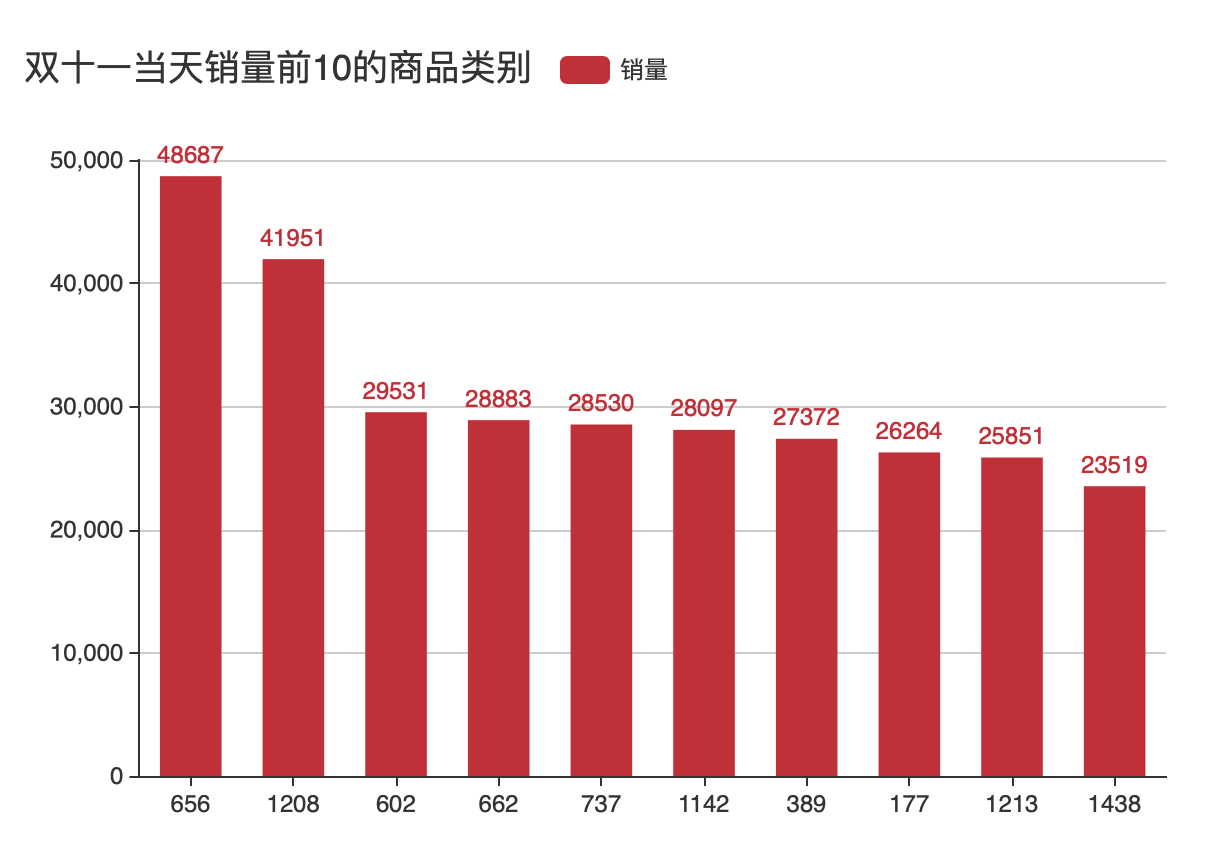
可视化实验三:双十一男女买家各个年龄段交易对比
数据处理
分析:
- 首先进行 map 操作,将数据处理成
(($日期, $用户行为, $年龄段, $性别), 1)样式 - 然后使用
filter()函数确定时间为 11 月 11 日,用户行为为购买,具体为日期month == 11, day == 11,用户行为action == 2 - 使用
map()函数将数据处理为(($年龄段, $性别), 1) - 使用
reduceByKey()计算出每个年龄段每个性别对应的条目数 - 为了方便后续生成对应的 JSON 格式数据,使用两个
sortBy()函数将数据按年龄段从小到大,性别 “女,男,未知” 顺序排序 - 将结果转换成 JSON 格式文件,并输出处理结果
数据处理核心代码如下:
1 | def transformationOps(sc: SparkContext): Unit = { |
转换成 JSON 文件
编写 toJSON_MultiBar() 函数,将 SparkRDD 处理的结果转换成 JSON 格式的文件,用于生成柱状图
- 使用阿里巴巴 Java 库
fastjson,新建一个JSONObject对象 - 新建四个数组分别存放:年龄段;女性、男性、其他在各个年龄段的交易量
- 使用循环,按行读取,按照不同性别筛选,将 SparkRDD 处理的结果放入对应的数组
- 导出,保存
函数代码如下:
1 | def toJSON_MultiBar(data: Array[((String, String), Int)], sc: SparkContext): Unit = { |
导出后的文件为 Spark 处理的文件,名称为 part-00000,需要手动将其加上 json 后缀为 part-00000.json
part-00000.json 文件内容为:
1 | { |
可视化呈现
使用 Tomcat 搭建本地 Java Web Server,编写 jsp 网页,将 *.json 文件导入,使用 ECharts 呈现
根据 ECharts 官方文档:异步数据加载和更新,使用 jQuery 工具将 json 文件导入
核心代码如下:
1 | // 基于准备好的dom,初始化echarts实例 |
可视化结果如图所示:
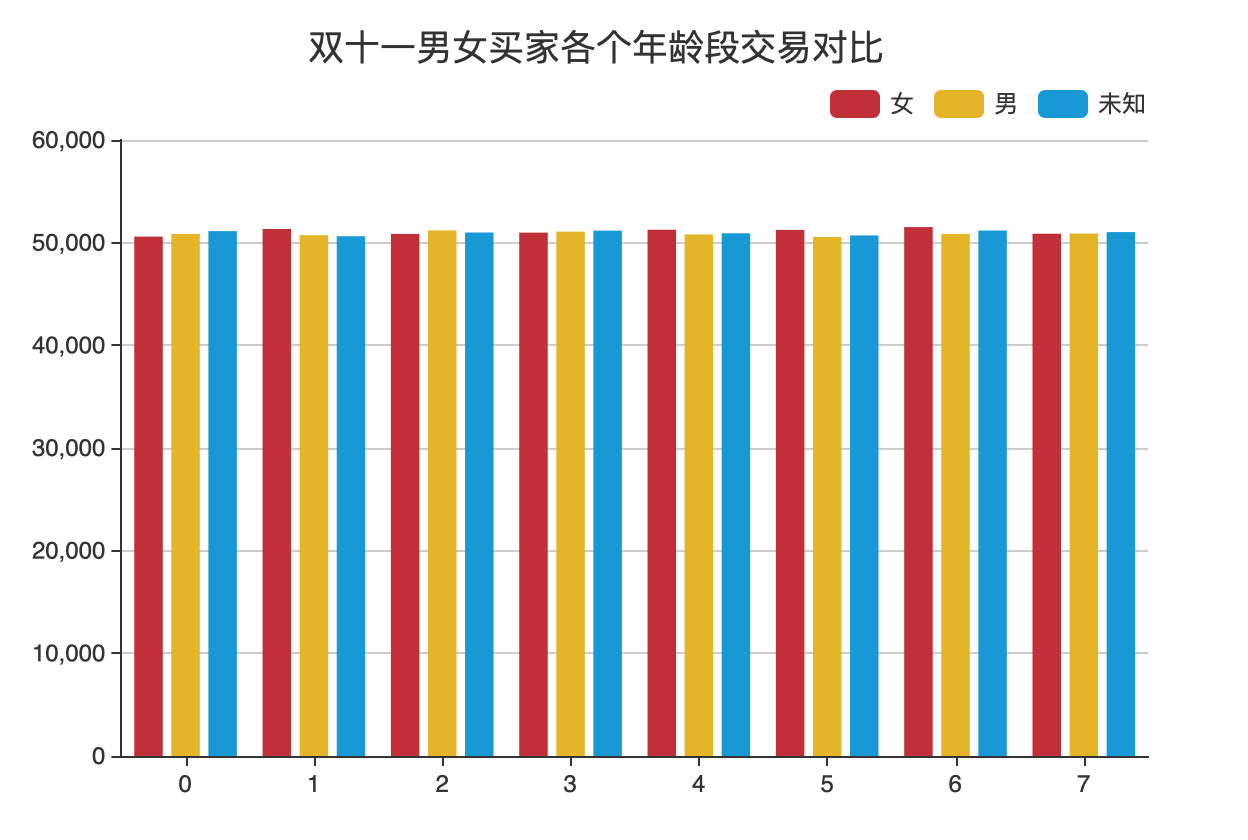
可视化实验四:双十一男女买家交易对比
数据处理
分析:
- 首先进行 map 操作,将数据处理成
(($日期, $用户行为, $性别), 1)样式 - 然后使用
filter()函数确定时间为 11 月 11 日,用户行为为购买,具体为日期month == 11, day == 11,用户行为action == 2 - 使用
map()函数将数据处理为($性别, 1) - 使用
reduceByKey()计算出每个性别对应的条目数 - 将结果转换成 JSON 格式文件,并输出处理结果
数据处理核心代码如下:
1 | def transformationOps(sc: SparkContext): Unit = { |
转换成 JSON 文件
编写 toJSON_Pie() 函数,将 SparkRDD 处理的结果转换成 JSON 格式的文件,用于生成饼状图
- 使用阿里巴巴 Java 库
fastjson,新建一个JSONObject对象 - 新建一个数组准备存放绘制 EChart 饼状图要求的
{"name":"","value":""}对 - 使用循环,按行读取,放入 SparkRDD 处理的结果
- 导出,保存
函数代码如下:
1 | def toJSON_Pie(data: Array[(String, Int)], sc: SparkContext): Unit = { |
导出后的文件为 Spark 处理的文件,名称为 part-00000,需要手动将其加上 json 后缀为 part-00000.json
由于原始数据中代表用户行为的数据为 0~3,数字对可视化呈现不直观,所以手动更改了 json 文件的对应内容
part-00000.json 文件内容为:
1 | { |
可视化呈现
使用 Tomcat 搭建本地 Java Web Server,编写 jsp 网页,将 *.json 文件导入,使用 ECharts 呈现
根据 ECharts 官方文档:异步数据加载和更新,使用 jQuery 工具将 json 文件导入
核心代码如下:
1 | // 基于准备好的dom,初始化echarts实例 |
可视化结果如图所示:
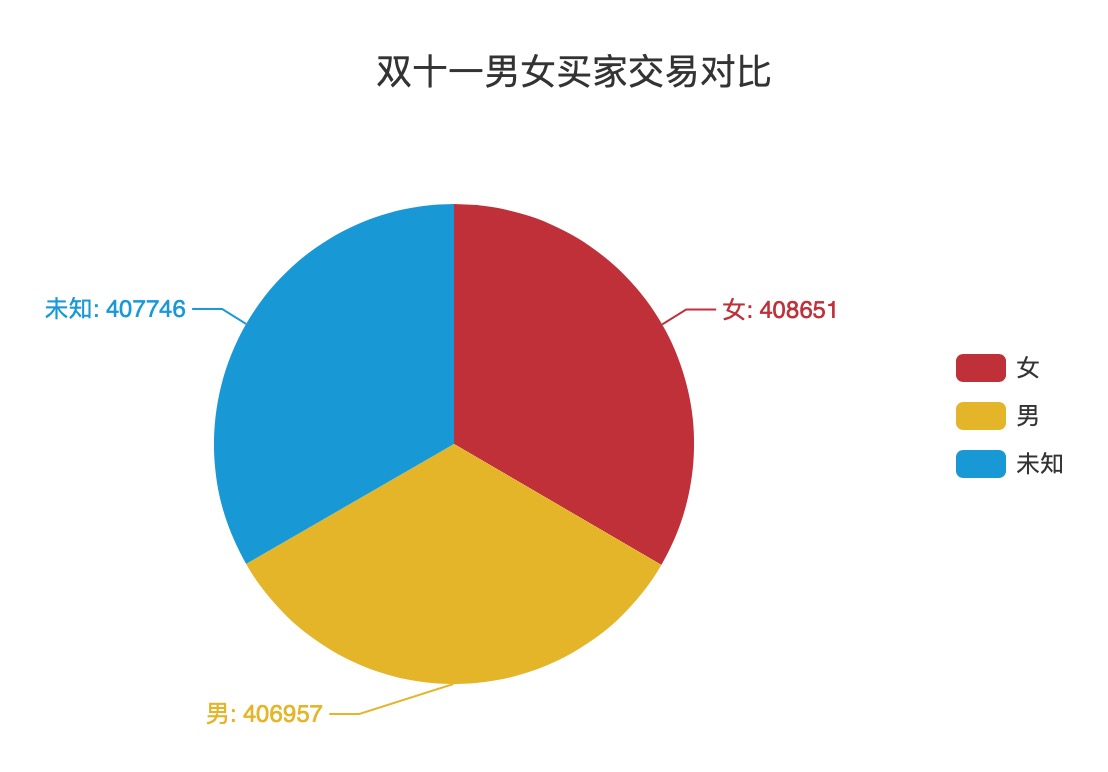
可视化实验五:各个省份的总成交量对比
数据处理
分析:
- 首先进行 map 操作,将数据处理成
(($省份, $用户行为), 1)样式 - 然后使用
filter()函数确定用户行为为购买,具体为用户行为action == 2 - 使用
map()函数将数据处理为($省份, 1) - 使用
reduceByKey()计算出每个省份对应的条目数 - 将结果转换成 JSON 格式文件,并输出处理结果
数据处理核心代码如下:
1 | def transformationOps(sc: SparkContext): Unit = { |
转换成 JSON 文件
编写 toJSON_Pie() 函数,将 SparkRDD 处理的结果转换成 JSON 格式的文件,用于生成饼状图
- 使用阿里巴巴 Java 库
fastjson,新建一个JSONObject对象 - 新建一个数组准备存放绘制 EChart 地图要求的
{"name":"","value":""}对 - 使用循环,按行读取,放入 SparkRDD 处理的结果
- 导出,保存
函数代码如下:
1 | def toJSON_Map(data: Array[(String, Int)], sc: SparkContext): Unit = { |
导出后的文件为 Spark 处理的文件,名称为 part-00000,需要手动将其加上 json 后缀为 part-00000.json
part-00000.json 文件内容为:
1 | { |
可视化呈现
使用 Tomcat 搭建本地 Java Web Server,编写 jsp 网页,将 *.json 文件导入,使用 ECharts 呈现
根据 ECharts 官方文档:异步数据加载和更新,使用 jQuery 工具将 json 文件导入
核心代码如下:
1 | // 基于准备好的dom,初始化echarts实例 |
可视化结果如图所示:
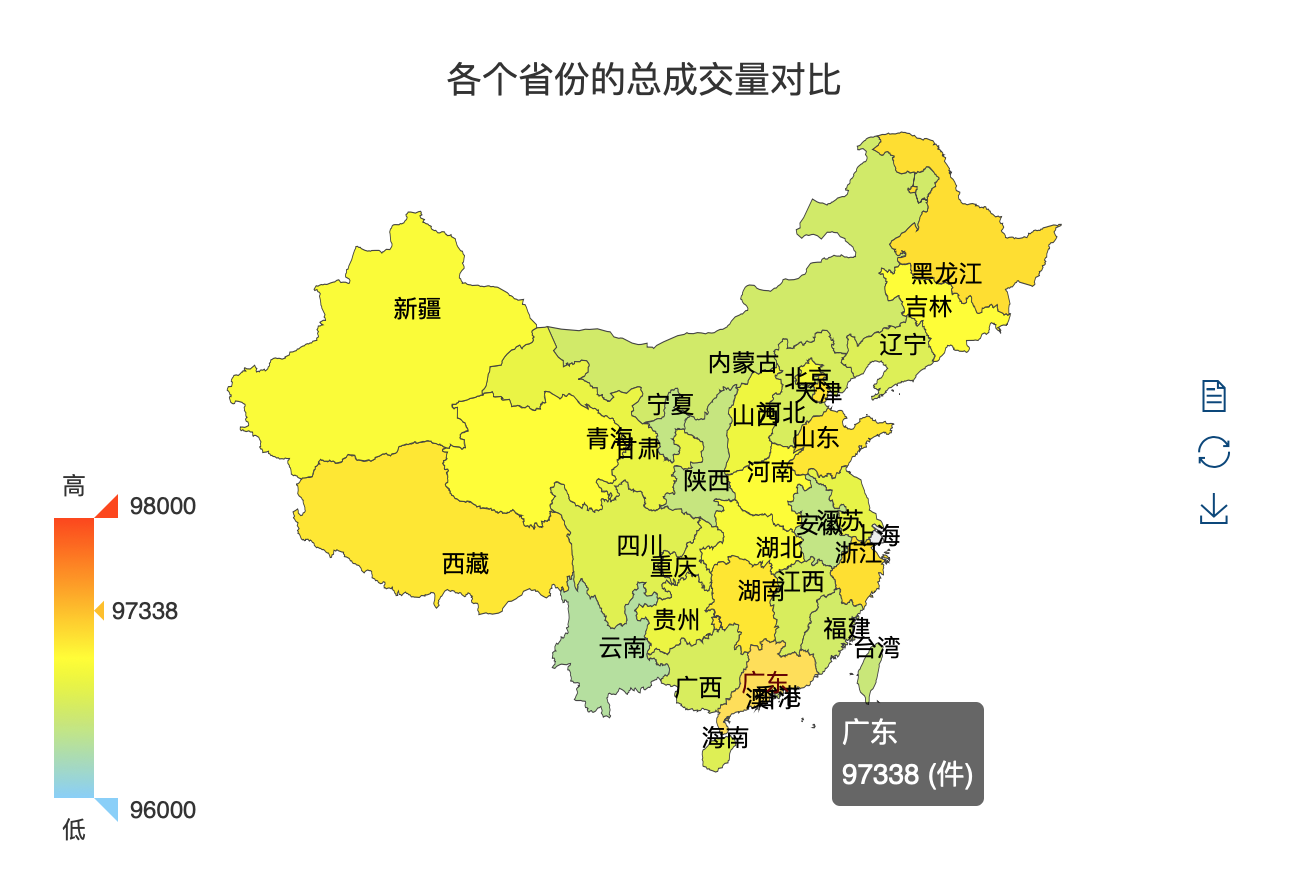
实验过程中发现的问题
在本次实验过程中发现了不少问题,有些通过在网络搜索解决了,但有些没有找到很好的解决方法,在此提出。
- 在编写可视化部分的代码时,使用 SparkRDD 生成的 JSON 格式的文件没有后缀,这时 jQuery 无法读取到文件的内容,必须手动更改
part-00000文件名为part-00000.json - 没有找到合适的方法修改 SparkRDD 里的数据,当绘制可视化实验一:双十一所有买家消费行为比例和可视化实验四:双十一男女买家交易对比时,由于原始数据中代表用户行为的数据为 0 ~ 3,代表用户性别的数据为 0 ~ 1,数字对可视化呈现不直观,所以手动需要更改 json 文件的对应内容。同样在绘制可视化实验五:各个省份的总成交量对比时,数据里有些省份的名字和
china.js中的省份名称不一样,比如北京和北京市,这样可视化的时候数据会不显示,也需要手动更改 JSON 文件内容。
Spark —— 淘宝双 11 数据分析